CoFRIDA: Self-Supervised Fine-Tuning for Human-Robot Co-Painting
Peter Schaldenbrand
Gaurav Parmar
Jun-Yan Zhu
James McCann
Jean Oh
ICRA 2024
Best Paper on Human-Robot Interaction
ICRA Expo 2024
Finalist for Best Demonstration
Best Paper on Human-Robot Interaction
ICRA Expo 2024
Finalist for Best Demonstration
Abstract
Prior robot painting and drawing work, such as FRIDA, has focused on decreasing the sim-to-real gap and expanding input modalities for users, but the interaction with these systems generally exists only in the input stages. To support interactive, human-robot collaborative painting, we introduce the Collaborative FRIDA (CoFRIDA) robot painting framework, which can co-paint by modifying and engaging with content already painted by a human collaborator. To improve text-image alignment--FRIDA's major weakness--our system uses pre-trained text-to-image models; however, pre-trained models in the context of real-world co-painting do not perform well because they (1) do not understand the constraints and abilities of the robot and (2) cannot perform co-painting without making unrealistic edits to the canvas and overwriting content. We propose a self-supervised fine-tuning procedure that can tackle both issues, allowing the use of pre-trained state-of-the-art text-image alignment models with robots to enable co-painting in the physical world. Our open-source approach, CoFRIDA, creates paintings and drawings that match the input text prompt more clearly than FRIDA, both from a blank canvas and one with human created work. More generally, our fine-tuning procedure successfully encodes the robot's constraints and abilities into a pre-trained text-to-image model, showcasing promising results as an effective method for reducing sim-to-real gaps.
CoFRIDA Overview

CoFRIDA Overview Offline, we fine-tune a pre-trained Instruct-Pix2Pix model on our self-supervised data. Online, the user can either draw or give the robot a text description. The Co-Painting Module takes as input the current canvas and text description to generate a pixel prediction of how the robot should finish the painting using the fine-tuned Instruct-Pix2Pix model. FRIDA predicts actions for the robot to create this pixel image and simulates how the canvas will look after the actions are taken. A robot (XArm, Franka, or Sawyer) executes the actions, updating the canvas. This process is repeated until the user is satisfied.
Self-Supervised Fine-Tuning
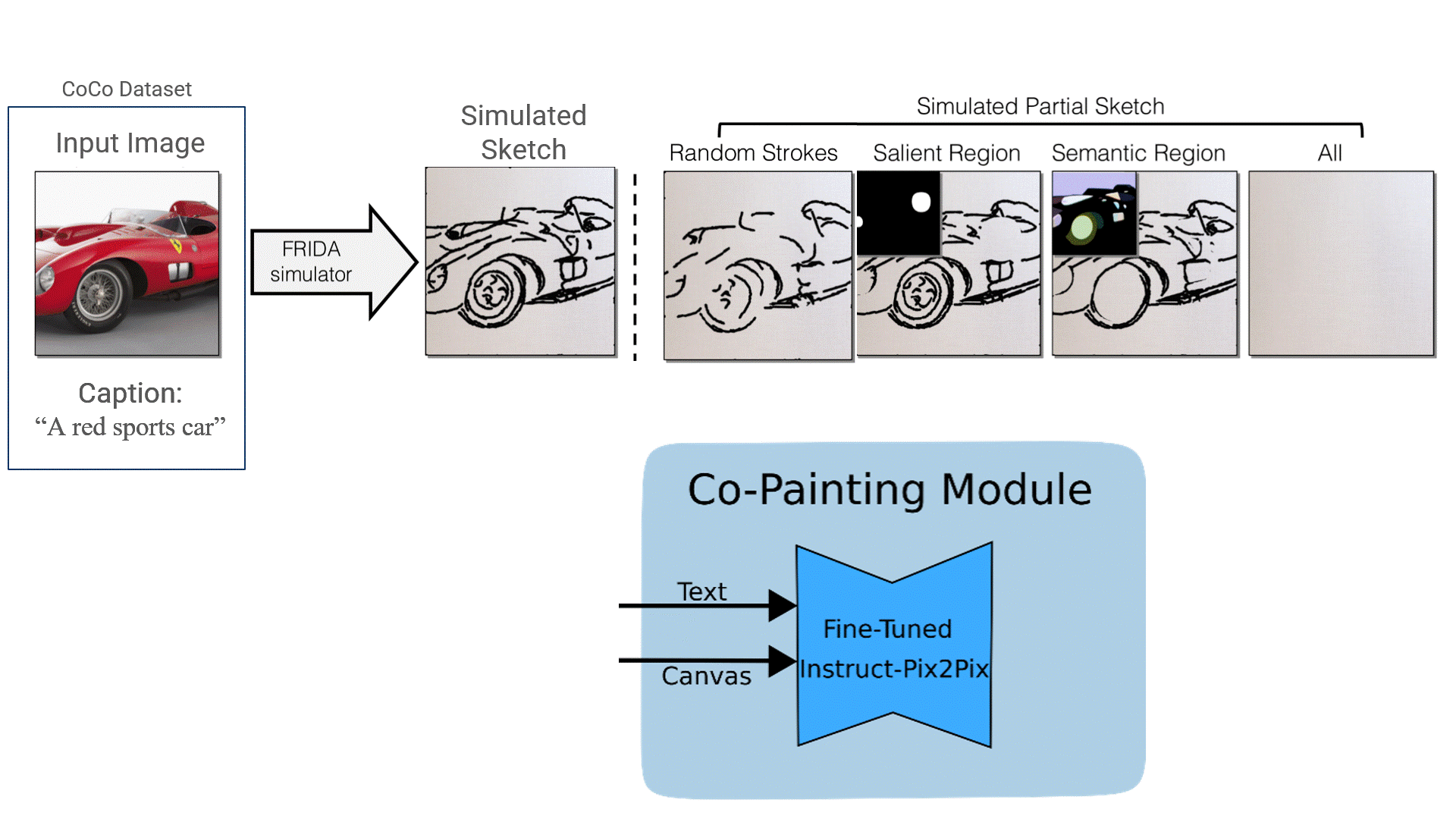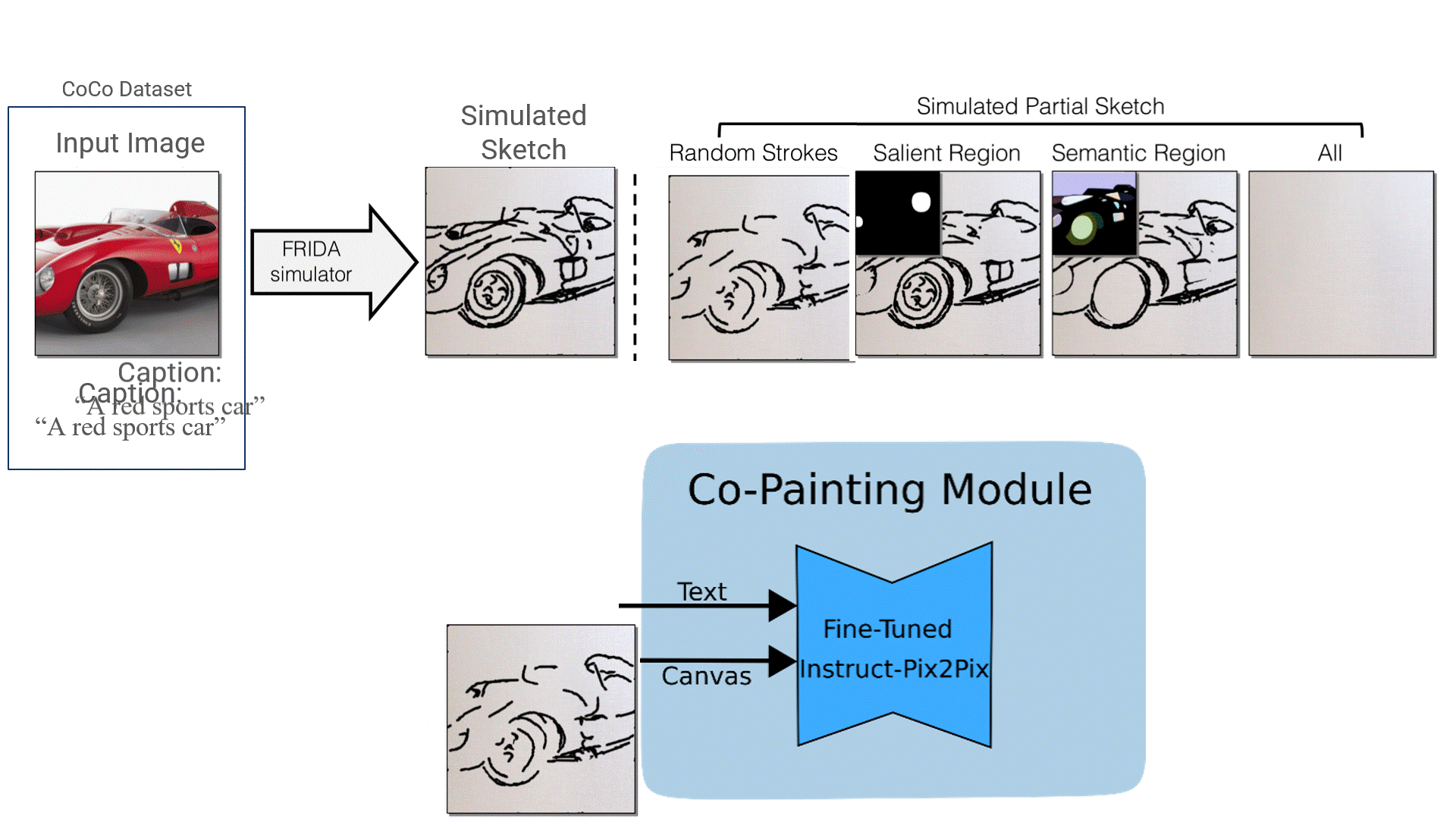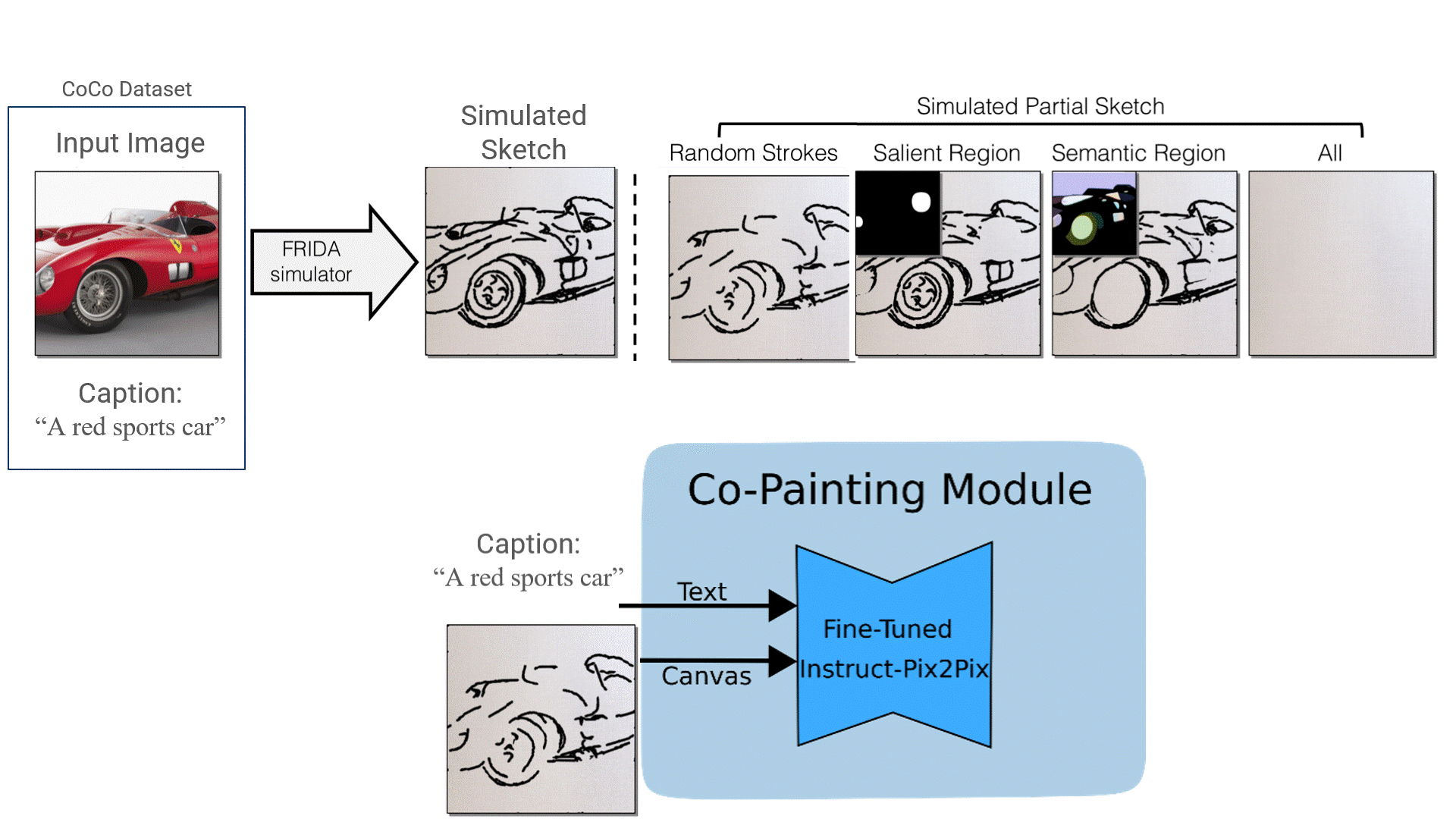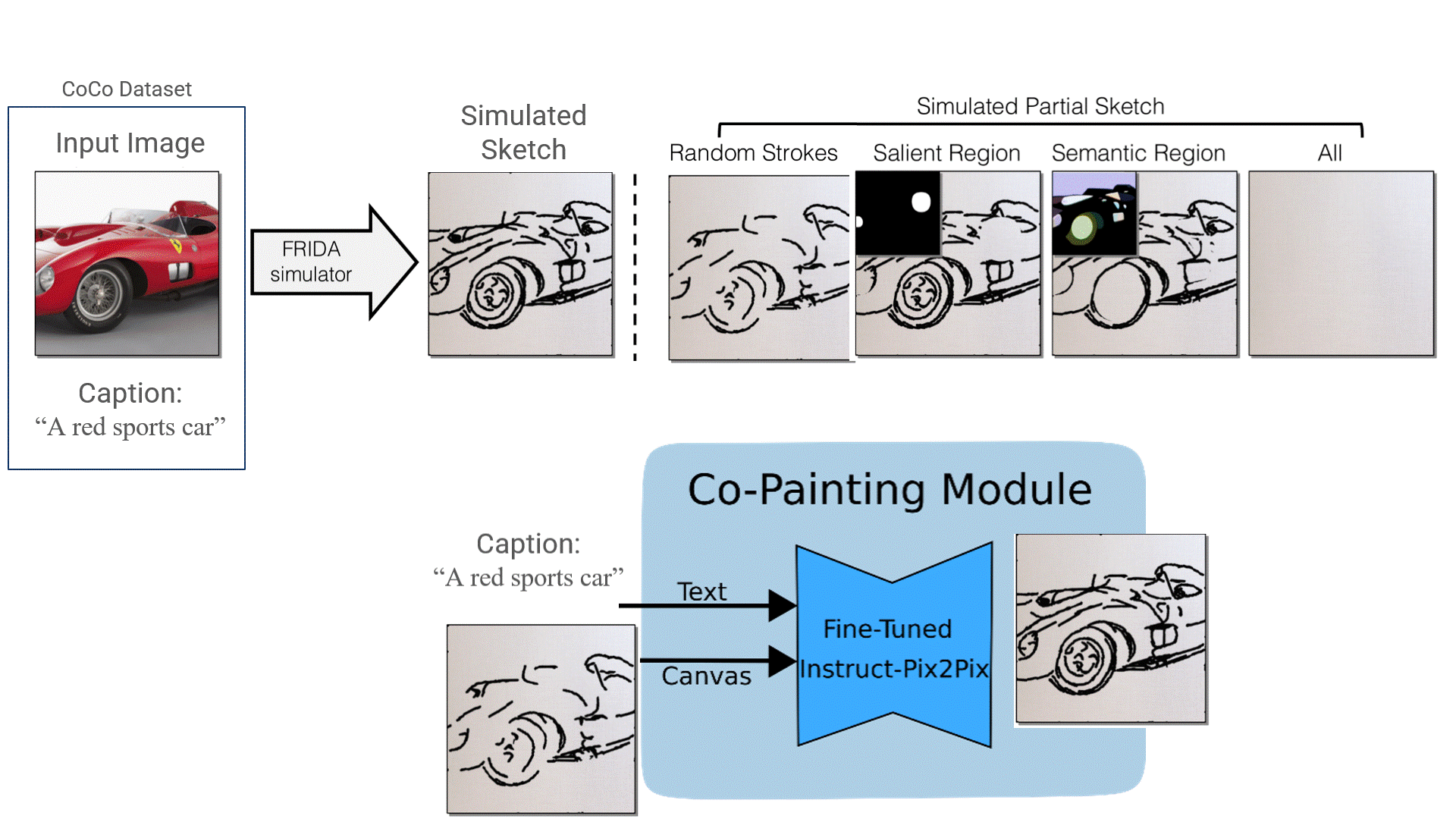
Self-Supervised Fine-Tuning Images from the CoCo dataset are converted into sketches or paintings using FRIDA's simulation. Strokes are removed to form partials sketches/paintings. Instruct-Pix2Pix is fine-tuned to predict the full sketch/painting conditioned on the partial and the caption.
Learning Robotic Constraints

Real-World Image Synthesis As opposed to pixel-based image synthesis, real-world image creation has limitations and constraints. For example, a robot may only have a Sharpie, be unable to erase, must use a canvas that already has paint or marker on it, and must act with limited time or finite number of actions. Our self-supervised fine-tuning technique is able to encode these robotic constraints into pre-trained image generators.

Encoding Real-World Constraints in Foundation Model Pretrained models tend to generate images that cannot be recreated with the tools available to the robot. The top left three images were generated by Stable Diffusion and cannot be replicated accurately due to various real-world, robotic constraints. Our self-supervised fine-tuning successfully encodes the constraints of the robot, such that generated images can be faithfully reproduced by the robot with little loss in meaning (right three images).
CoFRIDA Results

Co-Painting with CoFRIDA CoFRIDA is able to add content to canvases that engages with what is currently painted without destroying it. Even when CoFRIDA is trained on, for example only Sharpie drawings, it is capable of generalizing when a user draws/paints with an alternative media, like watercolors above.
Survey Results


Completing a Given Canvas We tested CoFRIDA's ability to add strokes to a given canvas conditioned on a text prompt. Partial drawings were created by generating images using Stable Diffusion conditioned on text from the Parti Prompt dataset, then simulated using only a few strokes with FRIDA. FRIDA, CoFRIDA without fine-tuning, and CoFRIDA then completed the drawing with the same text prompt. Participants in our survey were shown the text along with a CoFRIDA drawing and either FRIDA or CoFRIDA w/o fine-tuning. Participants selected which image, neither, or both fit the text description best. 24 unique participants found CoFRIDA's complete drawings fit the text description more closely than baseline methods.
More Results
Never-Ending Canvas By continuously scrolling a paper in CoFRIDA's view, a never-ending drawing can be created.
Mixed-Media Even when CoFRIDA only has a black marker and is trained on these images, it is able to recognize and plan with color content. In this example, a person paints using watercolors and collaborates with the robot.
Changing the Meaning of an Existing Drawing Completely CoFRIDA tries to add content to match the input text description given the current canvas. In this example, the current canvas content differs greatly from the given text description. CoFRIDA is able to alter the existing drawing to match the new meaning of the input text description.
